Transformer是一種深度學習模型架構,最初由Google Brain團隊在2017年發表了一篇論文 Attention Is All You Need 中所提出,主要應用於自然語言處理和序列處理任務。
Transformer模型由兩部分組成,即編碼器(Encoder)和解碼器(Decoder)。編碼器用於處理輸入序列,而解碼器用於生成輸出序列。主要創新引入了自我注意力機制(self-attention),讓模型能夠更好地理解序列資料中的內部關係和上下文,甚至效能優於傳統的RNN神經網路。
RNN模型對於輸入序列中,遠距離的依賴關係學習效果較差。前面的資料隨著時間的過去,其影響力逐漸減弱。這讓RNN難以處理長序列,例如自然語言處理中的長句子。
由於RNN的順序處理特性,不同時間步的計算無法同時進行,這導致模型的計算速度較慢,處理大規模輸入數據更加耗時。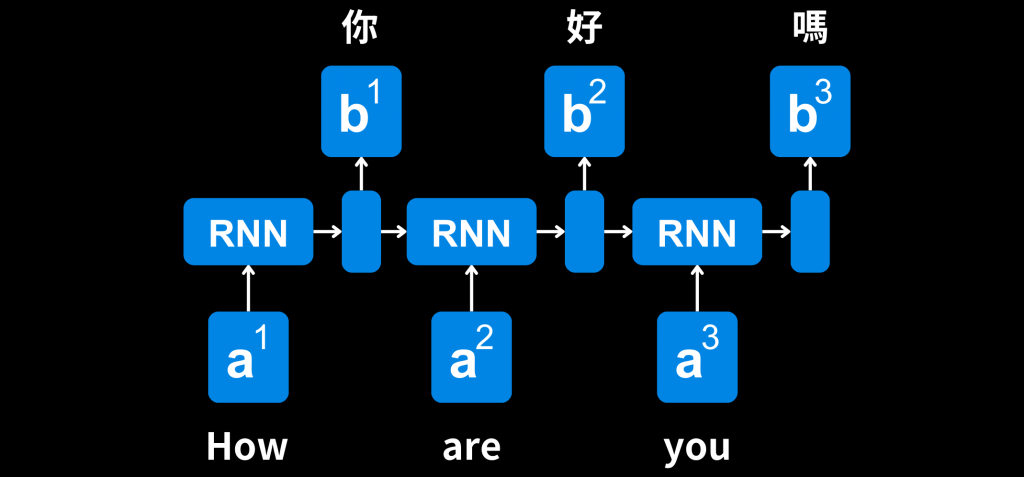
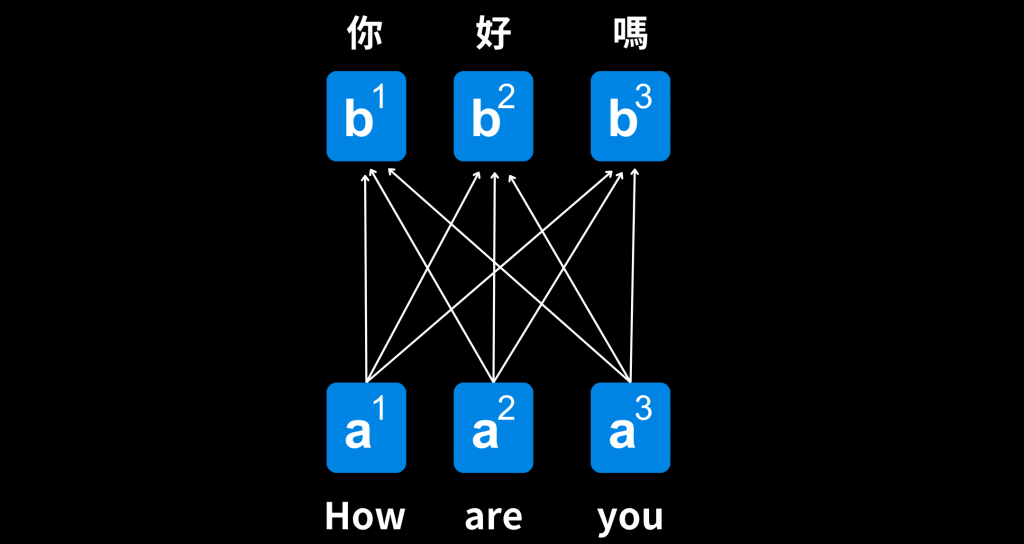
自注意力機制使得模型可以同時處理序列中的所有位置,這是因為它使用矩陣計算,而不像RNN一樣需要按照時間步驟依次處理。這種平行處理的能力大幅提高了計算效率,特別是對於長序列和大規模數據的處理,自注意力機制在速度上優於傳統的序列模型。
自注意力機制讓模型在處理序列時能夠理解所有的輸入,也就是每個位置都可以關注序列中的所有其他位置,而不僅僅是局部片段。這有助於模型更全面地理解輸入資料的語境和內容,進而提高了模型的表現。